





اینکه این کمبود تا چه میزان جدی است به این بستگی دارد که روند آموزش و استخدام دانشمندان داده و توسعهدهندگان توسط سازمانهای مرتبط تا چه حد جدی گرفته میشود. اما هوش مصنوعی بدون ناظر یا Driverless AI قادر است مدلهای یادگیری ماشینی را بدون نیاز به مهارتهای یادگیری ماشینی از طرف کاربران ایجاد کند. تا زمان انتشار این مقاله Driverless AI تنها سیستم یادگیری ماشینی خودکار است که به این شکل عرضه شده است. اما بدون شک ظرف یک سال آینده رقبای جدیدی چه بهصورت مجموعههای منبع باز یا خدمات مستقل رقیب آن خواهند شد.
اگر شرکتها بهجای استخدام دارندگان مدرک دکتری با حداقل 20 سال سابقه کار و ترجیحاً جوان، متخصصان این حوزه از جمله تحلیلگران، برنامهنویسان SQL و برنامهنویسان یادگیری ماشینی را به یک دیگر ارتباط دهند، دستیابی به اهداف مورد نیاز این صنعت سریعتر انجام خواهد شد. علاوه بر این اگر آنها استفاده از ابزارهايی مثل هوش مصنوعی بدون ناظر H2O.ai (Driverless AI ) که بخش قابل ملاحظهای از فرآیند یادگیری ماشین را خودکارسازی میکند، در دستور کار خود قرار دهند، میتوانند این گروهها را به طور چشمگیری کارآمدتر کنند. همان طور که مشاهده خواهیم کرد، هوش مصنوعی بدون ناظر یا Driverless AI یک سیستم یادگیری ماشینی است که به طور خودکار هدایت میشود و بدون نیاز به تخصص علم داده قادر به ایجاد و آموزش مدلهای شگفتانگیزی در طی مدت زمان بسیار کوتاه است. با وجود اینکه هوش مصنوعی بدون ناظر سطح مورد نیاز برای یادگیری ماشینی، قابلیتهای مهندسی و تخصص آماری را کاهش میدهد، اما نیاز به درک داده و آمار و الگوريتمهای یادگیری ماشینی که شما با آن سر و کار دارید را از بین نمیبرد.

شکاف مهارتهای علمی دادهها را کنار بگذارید
قبل از تجزیه و تحلیل داده چه با یادگیری ماشینی، یادگیری عمیق یا مدلهای آماری، باید آن را غربال و آماده کنید. طی فرآیند ساخت مدل، باید مهندسی ویژگی را بهمنظور ساخت فیلدهای جدیدی که ارتباط بیشتری با نتایج هدف نسبت به فیلدهای اصلی داده دارد انجام دهید که اغلب بعد از تجزیه مقدار منفرد (SVD) یا تحلیل کلاستر صورت میگیرد. انجام تمام این کارها بسیار خستهکننده است. ساخت مدلهای لایه به لایه شبکه عصبی عمیق و تنظیم دقیق پارامترهای آنها نیز خستهکننده و نیازمند کار زیاد، منابع پردازشی و حافظه بالا است.
طی سال گذشته حداقل چند مورد تلاش برای خودکارسازی یادگیری ماشینی صورت گرفته است که شامل Auto-sklearn, Auto-Weka, Prodigy, Google AutoML, Google Vizier و H2O.ai’s Driverless AI که موضوع این مقاله است میشود. بسته یادگیری عمیق منبع باز تحت هوش مصنوعی بدون ناظر H2O.ai، همچنین از یک مدل AutoML برخوردار است که روی تنظیم دقیق پارامترهای الگوريتمهای مختلف و یافتن بهترین ترکیب قابل استفاده برای حل مسئله تمرکز دارد.
علاوه بر مشکل در اختیار داشتن کارمند ماهر مورد نیاز برای ایجاد و بهینهسازی مدلها، هیچکس کاملاً نمیتواند پیشبینی مدلهای ساخته شده توسط سیستمهای یادگیری ماشینی که اغلب غیرخطی، غیرمونوتونی و غیرپیوسته هستند را درک کند. طی چند سال گذشته تلاشهای زیادی صورت گرفته تا پیشبینیهای یادگیری ماشینی به طور تقریبی تفسیر و «مسئله جعبه سیاه» حل شود. بسیاری از آنها نیز در ترکیب با هوش مصنوعی بدون ناظر مورد استفاده قرار گرفتهاند.
مسئله جعبه سیاه بهویژه در موارد کاربردهای برنامهریزی شده مثل مالی و پزشکی اهمیت پیدا میکند. تنها کافی نیست به یک متقاضی وام گفته شود که سیستم درخواست شما را رد کرده است. شما باید بتوانيد توضیح دهید چرا این درخواست رد شده است. به عنوان مثال، درآمد شما از میزان اعتبار مورد نیاز برای ضمانت این وام خیلی کمتر است یا خیلی از پرداختهای قبلی شما به تأخیر افتاده است. (شکل 1)
شکل 1
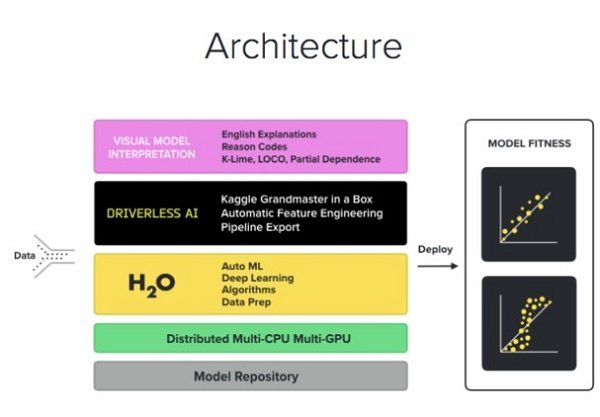
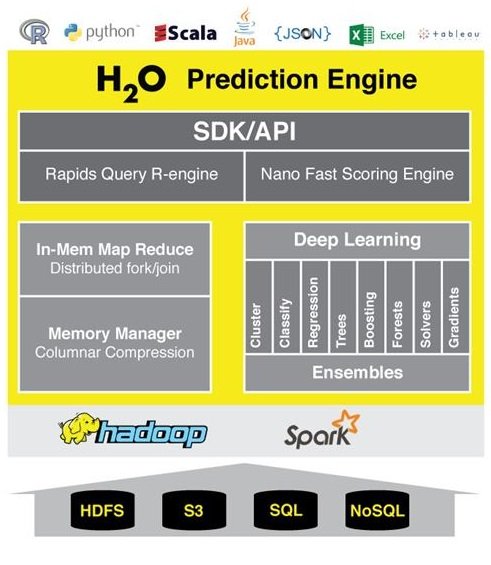
هوش مصنوعی بدون ناظر یک محصول وب اختصاصی است (نمودار معماری شکل 1 را مشاهده کنید) که روی پشته H2O.ai (نمودار معماری تصویر پایین شکل 1 را مشاهده کنید) با هدف تقلید از فرآیندهای مورد استفاده توسط استادان Kaggle برای ایجاد مدلهای عالی ساخته شده است. بخش زیرین پشته H2O.ai نیز بهشکل پیشساخته بهعنوان یک فایل JAR، چرخه پایتون و یک پکیج R موجود است. (شکل 2)
Kaggle یک سایت (https://www.kaggle.com/) ویژه علم داده است که مجموعه دادههای استاندارد را ارائه و مسابقاتی را برای تحلیل آنها برگذار میکند. برخی از این مسابقات دارای پشتیبانی مالی هستند و جوایز قابل توجهی نیز ارائه میکنند (به عنوان مثال برای جایزه اول رقابت چالش الگوریتم غربالگری مسافر TSA مبلغ 500,000 دلار در نظر گرفته شده است). همچنین، Kaggle دورههای آموزشی و محیطی آنلاین برای علم داده را نیز فراهم کرده است. هر چالش یک سرپرست دارد و تمام کاربران Kaggle توسط همگروهان خود رتبهبندی میشوند. در حال حاضر، در رتبهبندی Kaggle تعداد 95 استاد ارشد و 890 استاد وجود دارد. مطمئناً هزاران استاد دیگر در سطح دانشمندان داده مشغول کار در شرکتهای مختلف هستند که هنوز زمان و شانس رقابت در Kaggle را پیدا نکردهاند. اگر در حوزه علم دادهها مبتدی هستید پیشنهاد میکنم، ابتدا به مسیر https://www.kaggle.com/c/titanic بروید.
شکل 2
نصب و تنظیمات H2O.ai Driverless AI
نصب هوش مصنوعی بدون ناظر تنها بهسادگی انتخاب H2O.ai Driverless AI AMI در زمان ایجاد یک نمونه Amazon EC2 است. روی هر کلاود یا ماشین محلی پشتیبانی شدهای شما اصولاً Docker, nvidia-docker و Nvidia driver را نصب میکنید، سپس دایرکتوریهای استاندارد را اضافه میکنید، Driverless AI Docker container را دانلود و نصب و مجوز خود را اضافه میکنید. بعد از اجرا، Driverless AI container یک رابط تحت وب را روی پورت 12345 در اختیار شما میگذارد که میتوانید آن را با مرورگر کروم مشاهده کنید. نمایش پیشفرض (که در شکل 3 مشاهده میکنید) شامل فهرستی از آزمايشهای شما است.

شکل 3
پشتیبانی GPU در اوبونتو از برنامه nvidia-docker و Nvidia driver برای اتصال Driverless AI Docker container به Nvidia GPU استفاده میکند. هوش مصنوعی بدون ناظر میتواند از چند پردازنده گرافیکی و پردازنده مرکزی استفاده کند. هوش مصنوعی بدون ناظر از Kepler, Maxwell, Pascal و میکرومعماریهای Volta GPU پشتیبانی میکند. همچنین، روی پردازندههای گرافیکی Kepler K80 که نوع عرضه شده در نمونههای AWS P2 هستند بهخوبی کار میکند. هوش مصنوعی بدون ناظر از میکرومعماریهای قدیمیتر Tesla و Fermi پشتیبانی نمیكند.
مطلب پیشنهادی

با فرض اینکه شما هوش مصنوعی بدون ناظر را از روی کلاود اجرا میکنید، معمولاً با استفاده از Secure Copy (scp) داده را درون دایرکتوری داده از میزبان ماشین مجازی Driverless AI container بارگیری میکنید. این کانینر بهگونهای پیکربندی شده است تا در زمان ورود داده به طور پیشفرض از این دایرکتوری استفاده کند.
با توجه به اینکه میتوانید یک Driverless AI container را روی MacOS یا ویندوز 10 محلی خود نصب کنید، به یک ماشين با حداقل 16 گيگابايت رم و برای Docker به حداقل 8 گیگابایت رم نیاز خواهید داشت. اگرچه میتوانید با این پیکربندی آزمايشهای خود را انجام دهید، اما قادر به استفاده از آن برای کاربردهای جدی نخواهید بود و با کمبود حافظه و پشتیبانی پردازنده گرافیکی مواجه خواهید شد.
یادگیری ماشینی H2O.ai Driverless AI
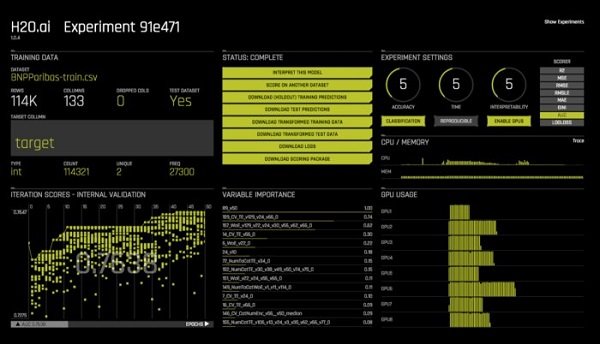
برای اجرای یک آزمايش، از طریق کروم روی پورت 12345 به سرور Driverless AI خود وارد شوید. روی دکمه New Experiment کلیک کنید، یک مجموعه داده آزمایشی را انتخاب کنید. در این مرحله شما صفحهای مطابق با تصویر زیر را مشاهده خواهید کرد. (شکل 4)
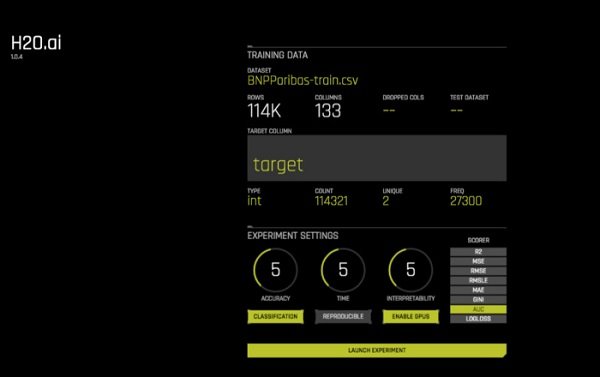
شکل 4
تنظیمات Accuracy کنترل چند پارامتر دیگر را تحت تأثیر قرار میدهد: حداکثر تعداد ردیفها، سطح گروه، اینکه آیا باید تغییر و تحولات هدف امتحان شود، آیا پارامترهای مدل XGBoost را باید تنظیم کرد، چه تعداد نمونه مستقل باید در الگوريتمهای تکوینی استفاده شود، چه تعداد مقیاس اعتبارسنجی در هر مدل استفاده شود و آیا باید تغییر انتخاب ویژگی انجام شود. تنظیمات Time تعداد دورههایی که باید اجرا شود را کنترل میکند. تنظیمات Interpretability مشخص میکند آیا باید از یک استراتژی انتخاب ویژگی برای نمایش تفسیر استفاده کرد. برای انجام یک آزمايش اولیه بهتر است از گزینههای پیشفرض برای این کنترلها استفاده کنید. (شکل 5)
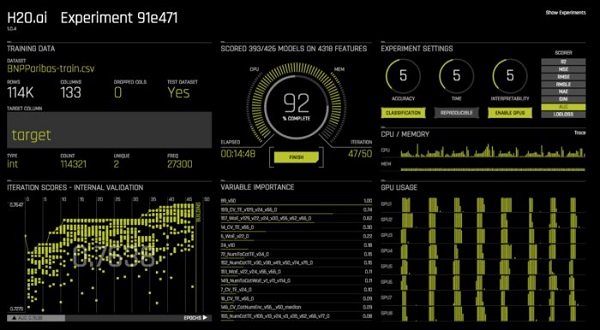
شکل 5
وقتی شما یک نمونه آزمایشی را راهاندازی میکنید، Driverless AI فرآيند مهندسی ویژگی را آغاز میکند که شامل تعلیم سریع و امتیازدهی به بسیاری از مدلها در حین اعمال تغییر و تحولات در فیلدهای داده برای ایجاد ویژگیهای جديد با پیشبینی بهتر قدرت بین دورهها است. در واقع، تغییر و تحولات اعمال شده به نوع داده بستگی دارد.
فیلدهای Text ممکن است TF-IDF و ویژگیهای شمارش کلمات را توليد کند. فیلدهای Numeric ممکن است بهگونهای تبدیل شوند تا مقادیر را به دستههای کوچکتر طبقهبندی کند. (شکل 6)
شکل 6
بعد از اینکه تمام دورهها ارزیابی شدند، Driverless AI یک آموزش کامل را اجرا و با مجموعه ویژگیهای نهایی شروع به تولید پیشبینی میکند. در این مرحله میتوانید تفسیرهای مدل را مشاهده کنید که به محاسبات کمی بیشتری نیاز دارد. (شکل 7)
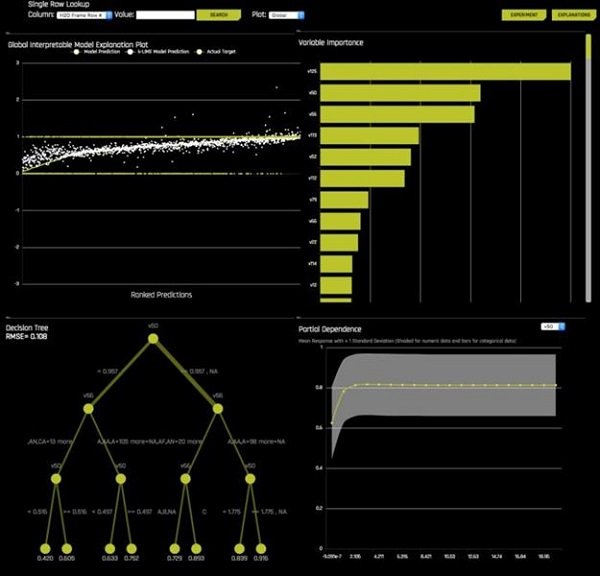
شکل 7
صفحه Model Interpretation شامل ترسیمی از طرح توضیحی از مدل تفسیری کلی، نمودار میلهای اهمیت آماری هر متغیر، ساختار درختی مدل جایگزین و ترسیمی از طرح مورد انتظار شرایط موردی است. همه اینها برای کمک به تولید توضیحات تقریبی از مدلهای بسیار دقیق با استفاده از تکنیک k-LIME انجام میشود. اساساً چیزی که در اینجا اتفاق میافتد، این است که Driverless AI یک تحلیل k-means را برای تولید کلاسترها اجرا میکند و مدلهای خطی کلاستر را با پیشبینی مدل Driverless AI هماهنگ میکند. از مدلهای محلی برای توضیح ردیفهایی که درون کلاسترهای بزرگ هستند و از مدلهای سراسری برای توضیح ردیفهایی که بیرون کلاسترهای بزرگ قرار دارند استفاده میشود. (شکل 8)

شکل 8
اگر بخش توضیحات را مشاهده کنید، میتوانید متغیرهایی را که بیشترین میزان مشارکت در مدلهای تفسیری سراسری داشتهاند و مدل کلاسترهای منفرد را ملاحظه کنید. برای مشاهده کلاسترهای مورد نظر خود از منوی کرکرهای Plot استفاده کنید. Driverless AI میتواند برای هرکدام از آزمايشهای یک پکیج رتبهبندی پایتون قابل دانلود تولید کند. شما برای اجرای این پکیجها به ابونتو 16.04 و بالاتر، پایتون 3.6 و مجموعهای از ماژولهای پایتون نیاز دارید. (شکل 9)
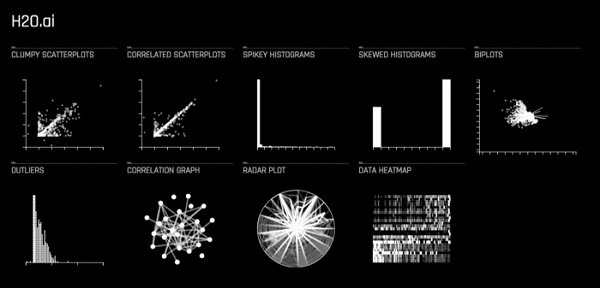
شکل 9
اگر روی یک مجموعه داده کلیک کنید، همان طور که در تصویر بالا مشاهده میکنید میتوانید عناصر کلیدی مرتبط با این مجموعه داده را بهشکل دیداری در اختیار داشته باشید. بعد از کلیک روی هرکدام از این عناصر دیداری میتوانید آن را در اندازه کامل مشاهده و دانلود کنید. برای کنترل بیشتر Driverless AI از طریق رابط کاربری وب میتوانید با استفاده از h2oai_client برنامههای کلاینت پایتون را آماده کنید.

ارزیابی یادگیری ماشین خودکار
در مجموع، Driverless AI تحسینبرانگیز است و شما از نتیجه کار آن شگفتزده خواهید شد. این شرکت میگوید استادان Kaggle آن که الگوريتمهای مورد نیاز این سیستم را فراهم میکنند نیز از عملکرد آن غافلگير شدهاند. مهندسی ویژگی و مدل آموزش اغلب هفتهها زمان میبرد تا به نتیجه قابل قبول دست پيدا كنيد. Driverless AI اغلب میتواند ظرف چند دقیقه یا چند ساعت یک پاسخ مناسب را ارائه کند. H2O.ai مدعی است Driverless AI نبوغ استادان ارشد Kaggle را در یک بسته در اختیار شما قرار میدهد. این درست است که متدهای استادان ارشد Kaggle در اختیار شما است، اما دیگرانی که در سازمان شما حضور دارند باید درباره کاری که انجام میدهید اطلاع داشته باشند. در غیر این صورت نمیتوانید درباره وضعیت عملکرد Driverless AI درست تصمیمگیری کنید. بدون برخی پیشزمینههای آماری، مباحث مهندسی ویژگی، کلاسترهای k-means و مدلهای خطی تولید شده برای شما بیمعنا هستند و نتایج بصری نیز شما را به نتیجه مطلوب نمیرساند.
ماهنامه شبکه را از کجا تهیه کنیم؟
ماهنامه شبکه را میتوانید از کتابخانههای عمومی سراسر کشور و نیز از دکههای روزنامهفروشی تهیه نمائید.
ثبت اشتراک نسخه کاغذی ماهنامه شبکه
ثبت اشتراک نسخه آنلاین
کتاب الکترونیک +Network راهنمای شبکهها
- برای دانلود تنها کتاب کامل ترجمه فارسی +Network اینجا کلیک کنید.
کتاب الکترونیک دوره مقدماتی آموزش پایتون
- اگر قصد یادگیری برنامهنویسی را دارید ولی هیچ پیشزمینهای ندارید اینجا کلیک کنید.





















نظر شما چیست؟