




با حذف وابستگی به زیرساختهای محاسباتی، یک شرکت نوپا قادر خواهد بود تا تمرکز و توجه خود را بر اصلاح و ارتقای کیفیت محصول خود معطوف دارد. به این ترتیب، موانع بر سر راه ورود استعدادهای بالقوه به بازار کاهش مییابد و هر شخص فقط با داشتن یک ارتباط اینترنتی و یک کارت اعتباری میتواند همانند سازمانهای صاحبنام از منابع محاسباتی در کلاس جهانی بهره گیرد. امروزه بزرگترین و محبوبترین سرویسهای اینترنتی شامل نتفلیکس، اینستاگرام، واین، فور اسکوئر و دراپباکس همگی از سرویسهای ابری تجاری استفاده میکنند.این نامها شاید به چشم کاربر نهایی قدری پرابهت و همسطح با ابرها بهنظر بیایند، اما در واقع به تجهیزات زمینی وابستگی شدیدی دارند! مراکز داده این شرکتها با ابعادی در اندازه یک زمین فوتبال بسیار پرهزینه و گرانقیمت است و تعجبی ندارد که عموماً شرکتهای غولپیکری همچون آمازون، گوگل و مایکروسافت آنها را اداره میکنند. هر کدام از این شرکتها مدلهای متنوعی از سرویسهایی با امکانات مختلف را ارائه میدهند که ماهیت آنها به نحوه تعامل مشتری با محیط محاسبات ابری بستگی مستقیم دارد. مدلهایی با پایینترین سطح که بهعنوان Infrastructure as a service یا «زیرساخت بهعنوان سرویس» (IaaS) شناخته میشوند، هر مشتری را به یک یا چند ماشین مجازی مجهز میسازند که روی تجهیزات فیزیکی تأمینکننده اجرا میشوند. برای مثال، پنج کامپیوتر مجازی را در نظر بگیرید که هر یک بهصورت استیجاری به پنج مشتری مختلف اختصاص مییابند.
افزون بر لیزینگ چنین ماشینهای مجازی، تأمینکنندگان IaaS امکان انتخاب سیستمعامل را برای اجرا روی این ماشینها برای مشتریان فراهم میکنند. مثال بارز از ابرهای IaaS سرویس Computer Engine شرکت گوگل و Elastic Compute Cloud شرکت آمازون است. در یک سطح بالاتر، ابرهای Platform-as-a-Service یا پلتفرم بهعنوان سرویس (PaaS) وجود دارند. این سرویسها شامل محیطی برای برنامهنویسان آنلاین هستند که روی تجهیزات شرکت تأمینکننده اجرا میشود. در چنین سرویسهایی مشتریان مجبور نیستند ماشینهای مجازی را مدیریت کنند، بلکه کافی است تا با استفاده از کتابخانههای نرمافزاری متنوع، رابطهای بصری برنامهنویسی و دیگر ابزارهای نرمافزاری مانند بانکهای اطلاعاتی و میانافزارها به ایجاد برنامههای کاربردی خود اقدام کنند و سپس، یک یا چند کامپیوتر مجازی برای تمام کارها بهصورت خودکار وارد عمل شوند. بهعنوان مثالهایی از ابرهای PaaS میتوان به Elastic Beanstalk آمازون، AppEngine گوگل، Azure مایکروسافت و Force.com شرکت SalesForce اشاره کرد. در سطوح بالاتر، ابرهای Software-as-a-Service یا همان نرمافزار بهعنوان سرویس (SaaS) قرار میگیرند. مشتریان این گونه سرویسها به اطلاع از لایههای زیرساختی زیرین یا پلتفرمهای محاسباتی هیچ نیازی ندارند و فقط بهسادگی از اپلیکیشنهای تحت وب یا بستههای کاربردی استفاده میکنند. این مدل محاسباتی ابری احتمالاً رایجترین مدلی است که مردم با آن آشنایی دارند. سرویسهایی مانند iWork شرکت اپل، Google Docs و Microsoft Office 365 برپایه این مدل طراحی شدهاند.
آیا این تنها روشی است که محاسبات ابری قادر به کار با آن هستند؟ در دانشگاه بولونای ایتالیا، تحقیقاتی حول یافتن راهبردهای جدید برای استفاده از محاسبات ابری بدون نیاز به مراکز تجهیزاتی عظیم در جریان است. هدف از این تحقیقات ایجاد فناوری نوین است که بتوان وظایف محاسبات ابری را همانند عملیات اشتراکگذاری فایلها، بهصورت نظیر به نظیر (peer-to-peer) و در بین کاربران به اشتراک گذاشت. شاید بتوان این کار را به نوعی «دموکراتیکسازی محاسبات ابری» تعبیر کرد. نمونههای نخست نرمافزار هنوز در مراحل بسیار ابتدایی قرار دارد، اما پیشرفتهای حاصل و مقایسه نتایج با تحقیقات مشابه در دیگر مناطق نشان میدهد که در مسیر صحیح گام برمیداریم.
قرارگیری فیزیکی تمام زیرساختهای مورد نیاز برای محاسبات ابری در یک مرکز داده (آن گونه که در حال حاضر انجام میگیرد) فواید واضح و مشخصی دارد. در این رویکرد، تأمین و پشتیبانی تجهیزاتی و عملیات نصب و نگهداری بهدلیل تمرکز در یک مکان فیزیکی با سهولت بیشتری صورت میگیرد و مقیاسپذیری اقتصادی موجب کاهش در هزینهها خواهد شد. از سوی دیگر، یک مرکز داده بزرگ و متمرکز مصرف انرژی بسیار زیادی داشته که اغلب با نیروی مورد نیاز یک شهرک کوچک قابل مقایسه است، ضمن اینکه میزان اتلاف انرژی حرارتی نیز معمولاً دردسرهای مخصوص به خود را همراه دارد.شاید «متمرکز» بودن مهمترین نقطه ضعف یک تأسیسات مرکز داده است. مهم نیست طراحی این مرکز تا چه اندازه هوشمندانه صورت گرفته باشد، با بروز کوچکترین مشکل کل مرکز داده از کار خواهد افتاد. تجهیزات برق اضطراری، ژنراتورهای پشتیبان و خطوط ارتباطی جایگزین کمکهای خوبی خواهند بود، اما هیچ یک قادر به مقابله با حوادث طبیعی مانند آتشسوزی، توفان، زلزله و سیل نیستند.
یکی دیگر از اشکالات تمرکزگرایی مراکز ابری، بحث جانمایی جغرافیایی آنها است. این مطلب میتواند به نفع مالک و به ضرر مشتریان تمام شود. برای مثال، میتوان به حالتی اشاره کرد که دولتها برای جابهجایی اطلاعات به خارج از مرزهای کشور محدودیتهایی وضع میکنند. در چنین وضعیتی مراکز داده مستقر در یک کشور برای کاربران خارج از آن کشور از دسترس بیرون خواهد بود. تأمینکنندگان سرویسهای ابری، این دغدغههای روزافزون را از طریق ایجاد چند مرکز در کشورهای مختلف و برقراری ارتباط بین آنها بهوسیله لینکهای اختصاصی پرسرعت مرتفع میکند. این راه حل نه تنها آنان را در برابر حوادث غیرمترقبه بیمه میکند، بلکه حق انتخاب مکان برای ذخیره اطلاعات را به مشتریان خواهد بخشید.
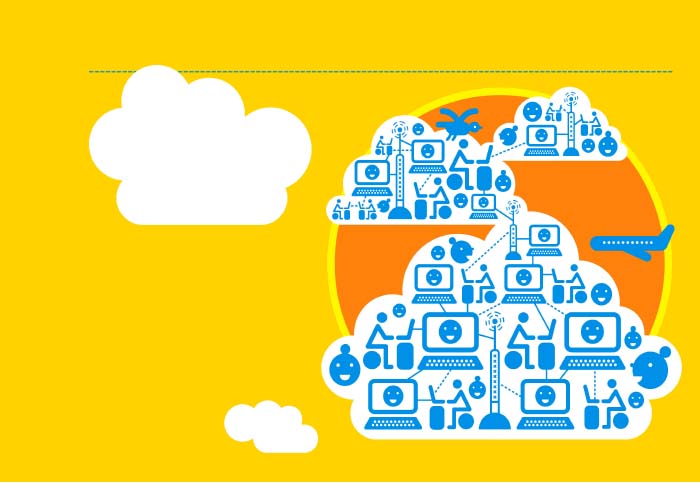
پراکندگی ابرها
با استفاده از نرمافزار مناسب، توزیع جغرافیایی سختافزارها میتواند به ایجاد یک منبع محاسباتی ابری یکنواخت منجر شود.
برخی از تأمینکنندگان سرویسهای محاسبات ابری تمام تخممرغهای خود (سختافزار) را در یک سبد (مرکز داده) قرار میدهند (آبی). برخی نیز از چند مرکز داده متصل به یکدیگر استفاده میکنند (نارنجی). یک توسعه منطقی مبتنیبر ابری نظیر به نظیر است که از مجموعهای از کامپیوترهای مجزا تشکیل شده است (زرد).
کامپیوترها در برخی از شبکههای P2P رفتاری شبیه به کارمندان شایعهساز دفاتر دارند. پروتکلهای مبتنیبر شایعه موجب جریان یافتن اطلاعات میشوند، حتی اگر برخی از کامپیوترها از سیستم خارج شوند و لینک را بشکنند (نارنجی).
از پروتکلهای مبتنیبر شایعه برای ایجاد شبکههای نظیر به نظیر ساختار نیافته استفاده میشود. برخی از آنها وظایف یک مشتری را انجام میدهند، در حالی که ترکیب دیگری در حال سرویسرسانی به مشتریان دیگر هستند (آبی و زرد).



اگر ملاحظات مرتبط با توزیع جغرافیایی زیرساختهای ابری را در تحلیلهای منطقی وارد کنیم، چه اتفاقی خواهد افتاد؟ در نتیجه، ابری تشکیل شده از میلیونها کامپیوتر مجزا خواهد بود که از طریق اینترنت و در سطح جهان به یکدیگر مرتبط شدهاند. این شبکه را نظیر به نظیر مینامیم؛ زیرا چنین شبکهای تمام ویژگیهای سیستمهای P2P را که برای به اشتراکگذاری فایلها طراحی شدهاند، دارند. ویژگیهایی مانند توزیع محتوا و شمای شبکههای پرداخت رمزگذاری شده، همانند آنچه در بیتکوین شاهد هستیم. بهطور کلی، یک ابر P2P میتواند با استفاده از تجهیزات محاسباتی، ذخیرهسازی و ارتباطی عادی بهوجود آید، همانند آنچه اکنون میتوان در خانههای کاربران یافت. شبکهای که تقریباً با هزینه سرمایهگذاری نزدیک به صفر ایجاد شده است. برای دستیابی به این هدف تمام مودمهای باند پهن، مسیریابها، ستتاپ باکسها، کنسولهای بازی، لپتاپها و پیسیها بهکار میآیند. چالش اصلی در این میان، بهکارگیری تمام این تجهیزات گوناگون و تبدیل آنها به یک زیرساخت قابل استفاده ابری و ارائه به مشتریان است. همچنین، باید اطمینان یافت که در این میان، ویژگیهای منحصر بهفرد ابری، یعنی تأمین آنی منابع درخواستی و مقیاسپذیری سرویس نیز حفظ شود. این کار بسیار دشوار خواهد بود، اما کافی است قدری به فواید آن فکر کنیم. نخست اینکه هیچ موجودیت واحد و مستقلی برای کنترل چنین شبکه ابری وجود نخواهد داشت. همانند دیگر ابزارهای P2P، ابر نظیر به نظیر نیز به شکل مالکیت عمومی ایجاد شده و بدون نیاز به اجازه یا صدور مجوز خاص از جانب هر مرجعی فعالیت خواهند کرد. برای مشارکت در چنین شبکههایی کافی است کاربران نرمافزار کلاینت را بهصورت محلی روی دستگاه خود نصب کنند. ارزش و کارایی چنین شبکهای به میزان مشارکت کاربران بستگی مستقیم دارد.
دومین امتیاز ناشی از این واقعیت است که اجزای تشکیلدهنده یک ابر P2P کوچک است و بههمین دلیل مصرف برق پایینی هم دارد. این موضوع باعث خواهد شد تا مصرف برق و همچنین نگرانیهای ناشی از حوادث طبیعی نیز بهشدت کاهش یابد. به این ترتیب، دغدغههای ایجاد گرما نیز بهحداقل خود خواهد رسید. هرچند قطعاً نمیتوان از چنین سرویسهایی توقع کیفیت تضمین شدهای همانند سرویسهای گوگل یا آمازون را داشت. ایده ایجاد یک منبع عظیم محاسباتی با استفاده از تعداد زیادی از کامپیوترهای منفرد جدید نیست و این کار قبلاً نیز انجام شده است. برای مثال، عملیات «رایانش داوطلبانه» (Volunteer-computing) که عبارت از انجام محاسبات دیگران از جانب افراد داوطلب روی دستگاههای خود است و قدمت زیادی دارد. رایانش داوطلبانه معمولاً نیازمند نصب یک نرمافزار مشخص است و در اوقاتی اجرا خواهد شد که کامپیوتر وظیفه خاصی برای انجام دادن ندارد و به قول معروف سرش خلوت است. این برنامه از چرخه محاسباتی بیکار سیستم استفاده و اطلاعات دریافت شده از تعدادی سرور مشخص را پردازش میکند و در انتها نتایج را به همان سرور آپلود خواهد کرد.این راهکار برای بسیاری از پروژههای علمی که در آنها یک کنترلر مرکزی اجزای محاسباتی منفرد را بهصورت یک مزرعه بهکار گرفته و نتایج حاصل را به شکل موازی مورد استفاده قرار میدهد، کارآمد است. اگر در این طراحی یکی از کامپیوترها در بازه زمانی تعریف شده پاسخ ندهد، مشکلی بهوجود نخواهد آمد و سیستم بهصورت خودکار وظایف را به سیستم داوطلب دیگری محول خواهد کرد.
شرکت Barkeley Open Infrastructure for Network Computing (به اختصار BOINC) یکی از معروفترین فعالان رایانشهای داوطلبانه است. از پروژههایی که روی پلتفرم این شرکت به انجام رسیده میتوان به SETI@home (برای تحلیل سیگنالهای رادیویی فضایی و جستوجوی دیگر موجودات هوشمند)، Rosetta@home (محاسبه ساختار پروتیینها) و Einstein@home (تشخیص امواج گرانشی زمین) اشاره کرد. گونه دیگری از رایانشهای داوطلبانه با نام Desktop grid شناخته شده است. در یک پروژه متعارف محاسباتی grid چند کامپیوتر با قدرت و توان محاسباتی بالا برای حل یک مشکل واحد با یکدیگر همکاری میکنند. Desktop grid به کاربران اجازه میدهد تا توان محاسباتی پیسی خود را برای این هدف به اشتراک بگذارند. BOINC از Desktop grid و EDGeS-Enabling Desktop Grid for e-Science پشتیبانی میکند. EDGeS پروژهای است که تعدادی از مؤسسههای اروپایی برپایه BOINC و XtremWeb (پروژه مرکز ملی تحقیقات علمی فرانسه) تعریف کرده است. موفقیت بسیاری از پروژههای رایانشهای داوطلبانه نشاندهنده ظرفیتهای نهفته در ابر P2P هم از بابت تعداد کامپیوترهای مشارکت داده شده و هم وسعت پراکندگی جغرافیایی آنان است. بهکارگیری چنین مجموعههایی از کامپیوترهای منفرد به طبع ما را با مشکلاتی مانند خرابی سختافزاری روبهرو خواهد کرد. علاوه بر آن، افرادی که کامپیوترهای خود را برای ابر به اشتراک میگذارند، کنترل زمان روشن و خاموش کردن دستگاههای خود را در اختیار دارند. بههمین دلیل، گاهی به افرادی که شبکههای P2P را اجرا میکنند، Churn نیز اطلاق میشود. به این ترتیب، نخستین وظیفه هر ابر P2P پیگیری تمام عملکردها و ابزارهای آنلاین داخل سیستم و تقسیم موزون منابع در بین کاربران است. این وظیفه باید کاملاً غیرمتمرکز باشد و با درنظر گرفتن تمام پارامترها و صرف نظر از انواع Churn صورت پذیرد.

برای مقابله با چنین چالشی، بسیاری از سیستمهای P2P از پروتکلهایی مبتنیبر شایعه (Gossip) استفاده میکنند. در اینجا Gossiping به حالتی اطلاق میشود که تعداد زیادی از کامپیوترها در یک شبکه غیرساختار یافته، اطلاعاتی را تنها از طریق تعداد محدودی از همسایگان مجاور خود با یکدیگر تبادل میکنند. پروتکلهای مبتنیبرشایعه بسیار پیشرفته است و برای مواردی مانند مقابله با انتشار بدافزار داخل شبکه، نشر اطلاعات در شبکههای اجتماعی و حتی محاسبه میزان همگامسازی پالسهای نوری در گروهی از کرمهای شبتاب بهکار گرفته میشود. دلیل استفاده از این پروتکلها در ابر P2P سادگی اجرا و توان بالای آنان در مواجهه با شبکههای پیچیده، حتی با وجود مشکلاتی مثل Churn است. در زمان اقدام به ساخت نمونه نخست از سیستم خود (که نام آن را سیستم ابری نظیر به نظیر P2PCS گذاشتیم) در دانشگاه بولونیا، از تعدادی پروتکلهای نامتمرکز مبتنیبر شایعه استفاده کردیم. این پروتکلها برای مواردی مانند یافتن ابزارهای روشن و متصل به شبکه، نظارت بر وضعیت کلی ابر، تقسیم منابع در دسترس و اختصاص آنان به چند زیرشبکه، یافتن منابع جدید و پشتیبانی از درخواستهای چندگانه از جانب دستگاههای متصل به شبکه بهکار گرفته میشوند. افزودن و ایجاد این قابلیتها قدم ابتدایی مهمی بهحساب میآید. با وجود این، هنوز نیازمندیهای بسیار زیادی برای ایجاد یک سیستم عملیاتی واقعی وجود دارد که تاکنون تنها برخی از آنان را فراهم کردیم.
اگر تمام تجهیزات در اختیار یک سازمان قرار داشته باشد، ساخت یک ابر P2P کار سرراستی خواهد بود. در چنین حالتی، حتی اگر بخشهای مختلف شبکه نیز در منازل افراد متعددی قرار داشته باشد، باز هم همانند وقتی که مودمهای باند پهن یا روترهای یک ISP در منازل مشترکان قرار داشته یا دستگاههای ستآپ باکس سرویسدهنده تلویزیون کابلی نزد مشترکان شرکت است، برقراری ارتباط بین آنها کار دشواری نخواهد بود. ابزارهای محاسباتی بسیار شبیه بههم هستند. بههمین دلیل، بهراحتی میتوان آنان را برای کار در یک محیط محاسباتی مشترک آماده کرد. همچنین، از آنجا که مالک تمام تجهیزات یک شرکت است که نرمافزار ابر P2P را نصب کرده است، قاعدتاً این اطمینان حاصل میشود که اطلاعات و محاسبات بهخوبی و تحت سیاستهای امنیتی سازمان مربوط در امنیت کامل خواهند بود. بهطریق مشابه، اگر ابر P2P از مجموعهای از کامپیوترهای متعلق به افراد مختلف یا کنسولهای بازی یا چیزهایی شبیه به اینها ایجاد شده باشد، این موارد درباره آن صدق نخواهد کرد. افرادی که از چنین ابرهایی استفاده خواهند کرد، مجبورند به غریبههایی اعتماد کنند که ممکن است کارهای مشکوک انجام دهند. همچنین، فراهمکنندگان تجهیزات نیز باید این طور فرض کنند که کاربران تمام زمان محاسبات را نخواهند بلعید.
اینها مشکلات بزرگی هستند که راه حل عمومی هم ندارند. اگر میخواهید صرفاً برخی اطلاعات خود را در یک ابر P2P ذخیره کنید، قضیه آسانتر خواهد شد؛ سیستم اطلاعات را خرد، رمزگذاری و در چند مکان ذخیره میکند. متأسفانه، هنوز راه حل کارآمدی برای اطمینان از امنیت اطلاعات پردازش شده روی دستگاههای تأیید نشده وجود ندارد. برای برخی مشکلات مشخص (مانند دستبرد به بیتکوین یا Mining Bitcoins) تأیید اطلاعات پردازش شده سریعتر از محاسبه مجدد آنان است. به این ترتیب، کلاینت قادر خواهد بود تا با بررسی مجدد و حذف نتایج نادرست، کاربر را از صحت عملیات انجام شده مطمئن سازد. برای مشکلاتی که فرآیند تأییدی مناسبی برای حل آنان وجود ندارد، بهترین روش برای شناسایی نفوذ و دستکاری، مقایسه نتایج بهدست آمده با نتایج اخذ شده از یک دستگاه دیگر است. مورد بعدی که در بسیاری از سیستمهای P2P شایع است، نیاز به ایجاد مشوقهای مناسب برای جذب افراد کافی در جهت مشارکت و همچنین ممانعت از سوء استفاده برخی کاربران است. در غیر این صورت، سیستم بهطور کامل رو به نابودی و اضمحلال خواهد رفت. بهکارگیری مشوق برای شرکتی که از ابزارهای اختصاصی خود برای ایجاد ابر استفاده میکند، کار سهل و آسانی بهشمار میآید. چنین شرکتهایی میتوانند از مشوقهای نقدی برای ایجاد ابر استفاده کنند و در صورت نصب تجهیزات در منازل نیز مشوق موجود به شکل امکان استفاده بهینهتر از همان سرویس باعث جذب مردم خواهد شد. سیستمهای رایانشهای داوطلبانه از داشتن چنین مشوقهای جذابی محروم هستند. اما با داشتن اهداف متعالی و قابل ستایش، در جذب دیگران برای در اختیار قرار دادن چرخههای آزاد پردازنده خود مشکل چندانی نخواهند داشت؛ اهدافی که از مهمترین آنان میتوان به کاهش مصرف انرژی، مقابله با گرمایش زمین و حفظ محیط زیست اشاره کرد. از این گذشته، چه کسی میتواند در برابر همکاری با SETI@home و مشارکت در ساخت تاریخ بهعنوان نخستین فرستنده رادیویی فرازمینی مقاومت کند؟ انتخاب مشوقهای مناسب برای سیستمهای P2P داوطلبانه امر حساسی است که باید با دقت به آن پرداخته شود. مشخصاً پیشرفتها در این زمینه هنوز در مراحل ابتدایی قرار دارند، اما پروژههای تحقیقاتی زیادی همراه تعدادی سیستم تجاری که تاکنون وارد بازار شدهاند، عقیده دارند که میتوان حداقل برای برخی اهداف مشخص، ابرهای P2P را بهصورت سودآور ایجاد کرد. برای مثال، فعالیتهای ما روی P2PCS نشان میدهد که امکان استفاده از پروتکلهای مبتنیبر شایعه برای شناسایی فعال منابع و نظارت بر سیستم امکانپذیر است.
دیگر محققان در دانشگاه مسینی ایتالیا (Cloud@home) ،INRIA (Cloud@Home) و همکاری با پروژه «نانودیتاسنتر» اتحادیه اروپا مفاهیم مشابهی را نمایان کردند. بهویژه «نانودیتاسنتر» پروژه بسیار جذابی است. محققان در این پروژه درگیر کار روی روش مدیریت شبکههای P2P تشکیل شده از گروههای بسیار دور با استفاده از Gateway سرویسدهندگان اینترنت هستند. چنین «نانودیتاسنتر»هایی بهدلیل نزدیکی بیشتر به کاربر نهایی میتوانند اطلاعات را با سرعت بهمراتب بیشتری نسبت به مراکز داده معدود، اما در حجم بالا منتقل کنند. برخی راه حلهای تجاری برای ذخیرهسازی ساختار یافته نیز برپایه ابر اصول محاسبات P2P طراحی شدهاند. برای مثال، نسخههای ابتدایی از ابر پشتیبانگیری Wulala به کاربران اجازه میدهد تا فضای خالی روی هارددیسک خود را معامله کنند. Sher.ly سرویس مشابهی را ارائه میکند، اما تفاوت در این است که بیشتر به سمت بخش تجاری تمایل دارد. این سرویس به شرکتها اجازه میدهد تا ماشینها و زیرساختهای خود را برای ایجاد یک ابر اختصاصی و امن برای به اشتراکگذاری فایلها به خدمت بگیرند.
همچنین، تعدادی سیستمهای منبع باز P2P وجود دارند که از آنها برای ذخیرهسازی ساختار یافته اطلاعات (همانند OceanStore که در دانشگاه بارکلی کالیفرنیا طراحی شده) یا انجام محاسبات (مانند سرویس OurGrid تهیه شده توسط دانشگاه دولتی کامپینا گراندا در برزیل) استفاده میشود. تعداد چنین پژوهشهای پیشتازانهای در حال حاضر خیلی زیاد نیست و در مقایسه با محیطهای ابری سنتی فاصله زیادی نیز با آنان دارند. چنانچه این مطالعات و تلاشها به بار بنشیند و محققان موفق به یافتن راهی برای غلبه بر مشکلات ذکر شده بشوند، قطعاً استفاده از ابر P2P به یکی از امورات عادی روزمره همه ما تبدیل خواهد شد؛ به گونهای که شاید حتی متوجه هم نشوید که در حال استفاده از چنین چیزی هستید.
ماهنامه شبکه را از کجا تهیه کنیم؟
ماهنامه شبکه را میتوانید از کتابخانههای عمومی سراسر کشور و نیز از دکههای روزنامهفروشی تهیه نمائید.
ثبت اشتراک نسخه کاغذی ماهنامه شبکه
ثبت اشتراک نسخه آنلاین
کتاب الکترونیک +Network راهنمای شبکهها
- برای دانلود تنها کتاب کامل ترجمه فارسی +Network اینجا کلیک کنید.
کتاب الکترونیک دوره مقدماتی آموزش پایتون
- اگر قصد یادگیری برنامهنویسی را دارید ولی هیچ پیشزمینهای ندارید اینجا کلیک کنید.






















نظر شما چیست؟