




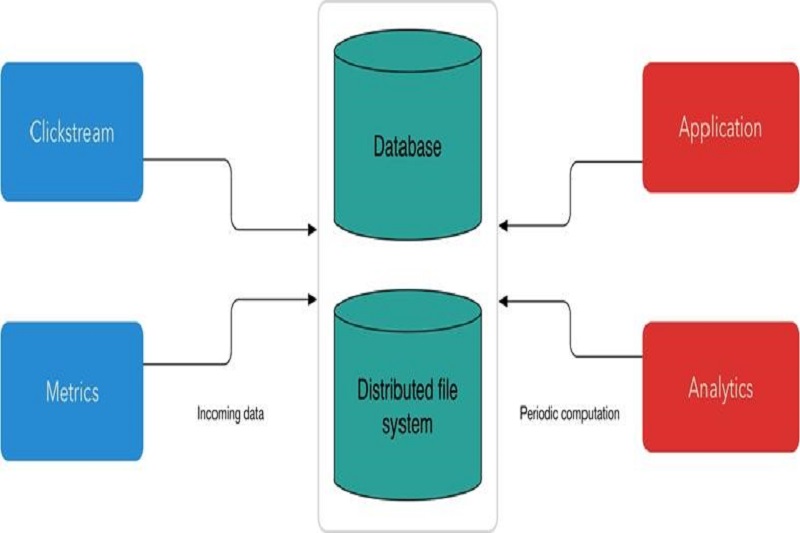
در مدل جریان داده، دادهها به صورت بستههای کوچک یا جریانهای بیانتها از منابع ورودی وارد سیستم میشوند. سپس، الگوریتمها برای پردازش و تحلیل دادهها به صورت آنلاین و به محض دریافت به کار گرفته میشوند. این مدل برخلاف مدلهای دستهبندی یا کاوش دادههای دستهبندی نشده، نیازی به دستهبندی کامل دادهها ندارد و به صورت تدریجی و با استفاده از رویکردهایی مانند الگوریتمهای آنلاین و تخمینی، به بررسی و تحلیل دادهها میپردازد.
مدل جریان داده به دلیل ویژگیهای خاص خود، نیازمند الگوریتمها و روشهای خاصی است که بتوانند با سرعت بالا و با استفاده از منابع محدود، به پردازش دادهها بپردازند. این مدل از تکنیکهایی مانند الگوریتمهای آنلاین، تخمینی، ترکیبی و بهینهسازی برای مدیریت و پردازش جریان دادهها استفاده میکند.
استفاده از مدل جریان داده در بسیاری از حوزهها مانند کاوش دادهها، تحلیل رویدادها، بهبود عملکرد سامانهها، شبکههای اجتماعی و سیستمهای توصیهگر، مدیریت منابع آب، تجارت الکترونیک و بسیاری موارد دیگر مورد استفاده قرار میگیرد.
آشنایی با الگوریتمهای جریانی دادهها
الگوریتمهای جریانی دادهها، الگوریتمهایی هستند که برای پردازش دادهها در محیط جریانی مورد استفاده قرار میگیرند. این الگوریتمها برای مقابله با چالشهایی مانند حجم زیاد دادهها، سرعت بالا و محدودیت منابع طراحی شدهاند. آنها به صورت تدریجی و به محض دریافت دادهها، به پردازش آنها میپردازند و نیازی به ذخیره کامل دادهها ندارند. به طور کلی، الگوریتمهای جریان داده به دو دسته تقسیم میشوند:
الگوریتمهای تک مرورگری (Single-Pass Algorithms)
در این الگوریتمها، دادهها به صورت تک تک مورد پردازش قرار میگیرند و بلافاصله پس از خوانده شدن فراموش میشوند. به عبارتی، الگوریتمها فقط یک بار از دادهها عبور میکنند. این الگوریتمها برای مسائلی که نیاز به حفظ تمام دادهها ندارند و میتوانند با استفاده از خلاصهها و تخمینها به نتیجه برسند، مناسب هستند.
الگوریتمهای تک مرورگری برای مسائلی که نیاز به حفظ تمام دادهها ندارند و میتوانند با استفاده از یک نمایش فشرده و خلاصه از دادهها به نتیجه مورد نظر برسند، مناسب هستند. در ادامه، تعدادی از الگوریتمهای تک مرورگری معروف را بررسی میکنیم:
- الگوریتم تخمین تعداد عناصر یکتا (Distinct Elements Estimation): این الگوریتمها برای تخمین تعداد عناصر یکتای موجود در جریان دادهها استفاده میشوند. از جمله معروفترین الگوریتمهای این دسته، الگوریتمهای Bloom Filter و Count-Min Sketch میباشند.
- الگوریتمهای تخمین مقادیر آماری (Statistical Value Estimation): این الگوریتمها برای تخمین مقادیر آماری مانند میانگین، واریانس، درصدیل و کوانتایلها از دادهها استفاده میشوند. الگوریتمهایی مانند تخمینگر تمامی (Sticky Sampling) و تخمینگر تمامی تکدستهای (Sticky Sample Sketch) در این دسته قرار میگیرند.
- الگوریتمهای تخمین توزیع احتمال (Probability Distribution Estimation): این الگوریتمها برای تخمین توزیع احتمال دادهها استفاده میشوند. الگوریتمهایی مانند تخمینگر توزیع احتمال آمیخته (Mixture Distribution Estimator) و تخمینگر توزیع احتمال کوانتایلی (Quantile Distribution Estimator) در این دسته قرار دارند.
الگوریتمهای تک مرورگری با استفاده از روشهایی مانند خلاصهسازی، نمونهبرداری تصادفی، تخمین و تقریب برای پردازش دادهها در محیط جریانی استفاده میکنند. آنها برای مسائلی که نیاز به حفظ تمام دادهها ندارند و میتوانند با استفاده از خلاصهها و تخمینها به نتیجه برسند، مناسب هستند.
الگوریتمهای چند مرورگری (Multiple-Pass Algorithms)
الگوریتمهای چند مرورگری الگوریتمهایی هستند که برای پردازش دادهها در محیط جریانی طراحی شدهاند و برخلاف الگوریتمهای تک مرورگری، برای دسترسی به نتیجه نهایی نیاز به مرور چندگانه دادهها دارند. در این الگوریتمها، دادهها به صورت متوالی خوانده میشوند و در هر مرور، بخشی از پردازش انجام میشود و نتیجه موقت ذخیره میشود. در مراحل بعدی، از نتایج موقت قبلی استفاده میشود تا به نتیجه نهایی برسد.
الگوریتمهای چند مرورگری برای مسائلی که نیاز به دسترسی به دادههای گذشته یا کلیت دادهها برای حل مسئله دارند، مناسب هستند. این الگوریتمها معمولا برای محاسبات پیچیدهتر و دقیقتر از الگوریتمهای تک مرورگری استفاده میشوند. اما هزینه بیشتری در ارتباط با دسترسی مکرر به دادهها و نیاز به ذخیره بخشی از دادهها دارند. از الگوریتمهای چند مرورگری مطرح به موارد زیر باید اشاره کرد:
- الگوریتم ترکیب محاسباتی (Combining Computations): در این الگوریتم، پردازش دادهها به چندین مرحله تقسیم میشود و در هر مرحله، بخشی از عملیات انجام میشود. نتایج موقت هر مرحله برای استفاده در مراحل بعدی ذخیره میشوند و در نهایت، نتیجه نهایی بر اساس ترکیب این نتایج محاسبه میشود.
- الگوریتم تقسیم و حل (Divide and Conquer): در این الگوریتم، مسئله اصلی به چندین زیرمسئله کوچکتر تقسیم میشود و برای هر زیرمسئله، یک مرور جداگانه انجام میشود. سپس نتایج به دست آمده از زیرمسئلهها با هم ترکیب میشوند تا به نتیجه نهایی برسیم.
- الگوریتمهای بازیابی اطلاعات (Information Retrieval Algorithms): در این الگوریتمها، دادهها به چندین مرحله تقسیم میشوند و در هر مرحله، بخشی از عملیات بازیابی اطلاعات انجام میشود. اطلاعات مورد نیاز از دادههای قبلی استخراج میشوند و در مراحل بعدی استفاده میشوند تا به نتیجه نهایی برسیم.
الگوریتمهای چند مرورگری در حوزههای مختلفی از جمله پردازش تصویر، پردازش زبان طبیعی، بیگدیتا و سیستمهای توزیع شده استفاده میشوند. این الگوریتمها به دلیل قابلیت پردازش موازی و استفاده از اطلاعات گذشته، میتوانند بهبود قابل توجهی در کارایی و دقت مدلها و سیستمهای پردازش دادهها داشته باشند.
مزیتها و معایب الگوریتمهای تک مرورگری و چند مرورگری چیست؟
الگوریتمهای تک مرورگری و چند مرورگری هر کدام مزایا و معایب خود را دارند. در زیر به برخی از مزایا و معایب هر دو نوع الگوریتم اشاره خواهم کرد:
مزایای الگوریتمهای تک مرورگری:
- سادگی: الگوریتمهای تک مرورگری معمولا سادهتر و آسانتر در پیادهسازی هستند. نیاز به ذخیره موقت دادهها و مراحل طولانی پردازش ندارند.
- عملکرد سریع: به دلیل اینکه در یک مرور از دادهها عبور میکنند و نتیجه نهایی را بدست میآورند، میتوانند عملکرد سریعتری نسبت به الگوریتمهای چند مرورگری داشته باشند.
معایب الگوریتمهای تک مرورگری:
- نیاز به حافظه بیشتر: به دلیل عدم دسترسی به دادههای گذشته، الگوریتمهای تک مرورگری ممکن است نیاز به ذخیره موقت بخشی از دادهها داشته باشند تا در صورت نیاز به آنها برگردند. این موضوع میتواند نیاز به حافظه بیشتری را ایجاد کند.
- عدم قابلیت استفاده از اطلاعات گذشته: در الگوریتمهای تک مرورگری، اطلاعات گذشته در دسترس نیستند و فقط بر اساس دادههای حال حاضر پردازش انجام میشود. این ممکن است باعث از دست رفتن اطلاعات مهم یا عدم استفاده کامل از مواردی مثل الگوها یا روابط بین دادهها شود.
مزایای الگوریتمهای چند مرورگری:
- دسترسی به اطلاعات گذشته: الگوریتمهای چند مرورگری قابلیت دسترسی به دادههای گذشته را دارند. این اطلاعات میتوانند در پردازش بعدی مورد استفاده قرار گیرند و اطلاعات کاملتری را به الگوریتم ارائه دهند.
- دقت بالا: با استفاده از اطلاعات گذشته و انجام چندین مرور از دادهها، الگوریتمهای چند مرورگری معمولا دقت بالاتری در پردازش دادهها دارند.
معایب الگوریتمهای چند مرورگری:
- پیچیدگی: الگوریتمهای چند مرورگری معمولا پیچیدهتر هستند و نیازمند مراحل بیشتری از پردازش هستند. این میتواند موجب افزایش هزینه محاسباتی و زمان اجرا شود.
- مدیریت حافظه: الگوریتمهای چند مرورگری برای ذخیره موقت دادهها و نتایج مراحل قبلی نیاز به مدیریت مناسب حافظه دارند. این ممکن است به مدیریت پیچیدهتری نیاز داشته باشد و مشکلاتی مانند مصرف حافظه بیشتر را به همراه داشته باشد.
به طور کلی، انتخاب بین الگوریتمهای تک مرورگری و چند مرورگری وابسته به مسئله مورد نظر، نیازهای دقت و سرعت، منابع موجود و شرایط محیطی است. هر دو نوع الگوریتم مزایا و معایب خود را دارند و برنامهنویسان و مهندسان باید با توجه به شرایط و مسئله مورد بررسی، الگوریتم مناسب را انتخاب کنند.
چند مثال از الگوریتمهای جریان داده در تحلیل جریانهای حسگری
الگوریتمهای جریان داده (Streaming Algorithms) الگوریتمهایی هستند که برای پردازش دادههای جریانی که به صورت پیوسته و با نرخ بالا وارد میشوند، طراحی شدهاند. این الگوریتمها به صورت تدریجی و در حالتی که داده به صورت تکهتکه و با محدودیتهای منابع زمانی و حافظه وارد میشود، تحلیل و پردازش داده را انجام میدهند. در زیر چند مثال از الگوریتمهای جریان داده در تحلیل جریانهای حسگری را بیان میکنیم:
الگوریتم تخمین تعداد عناصر منحصر به فرد (Distinct Elements Estimation Algorithm): این الگوریتم برای تخمین تعداد عناصر منحصر به فرد در یک جریان داده استفاده میشود. یکی از معروفترین الگوریتمها در این زمینه الگوریتم "HyperLogLog" است که با استفاده از توابع هش و تکنیکهای احتمالاتی، تخمینی از تعداد عناصر منحصر به فرد در جریان داده ارائه میدهد.
الگوریتم بیت داخلی (Bloom Filter): بلوم فیلتر یک الگوریتم جریان داده است که برای بررسی وجود یک عنصر در یک مجموعه به صورت فشرده استفاده میشود. این الگوریتم دادههای ورودی را با استفاده از یک جدول بیتی تحققپذیر میکند و از توابع هش برای ایجاد امضایی از دادهها استفاده میکند. بلوم فیلتر به صورت سریع و با استفاده از حافظه کمتر، میتواند وجود یا عدم وجود یک عنصر را بررسی کند، اما با احتمال خطا کوچک.
الگوریتم هیت-کانتر (Count-Min Sketch): این الگوریتم برای تخمین تعداد تکرارهای عناصر مختلف در یک جریان داده استفاده میشود. از توابع هش برای ایجاد جدول ضرب کنتر استفاده میشود و با افزودن دادهها، شمارش تعداد تکرارهای آنها در جریان داده انجام میشود. این الگوریتم با استفاده از حافظه کم، تخمینی از تعداد تکرارها را ارائه میدهد، اما با احتمال خطا کوچک.
الگوریتم تخمین میانگین (Approximate Mean Algorithm): این الگوریتم برای تخمین مقدار میانگین یک جریان داده استفاده میشود. این الگوریتم به صورت تدریجی و در حالتی که داده به صورت پیوسته وارد میشود، تخمینی از میانگین را محاسبه میکند. به طور معمول، از روشهایی مانند روشهای تخمین با وزن (Weighted Estimation) و روشهای استنتاجی (Sampling-based Methods) برای انجام این کار استفاده میشود.
موارد یاد شده تنها چند مثال از الگوریتمهای جریان داده در تحلیل جریانهای حسگری هستند. همچنین، الگوریتمهای دیگری نیز وجود دارند که برای تحلیل و پردازش دادههای جریانی استفاده میشوند و به وفور در مطالعات مربوط به حسگرها و اینترنت اشیا مورد استفاده قرار میگیرند.
Basic Probability و Tail Bounds چیست؟
احتمالات پایه (Basic Probability) احتمالات پایه به بخشی از نظریه احتمالات گفته میشود که به مطالعه و تحلیل رویدادها و احتمالات مرتبط با آنها میپردازد. این حوزه شامل مفاهیم و قوانین اساسی احتمالات مانند فضای نمونه، رویدادها، احتمال، قاعده جمع، قاعده ضرب و احتمال شرطی است. با استفاده از احتمالات پایه، میتوانیم مسائل مختلفی را مدلسازی کرده و احتمال وقوع یا عدم وقوع رویدادها را تخمین بزنیم.
محدودههای دم (Tail Bounds) محدودههای دم یا حدود دم، یکی از مفاهیم مهم در نظریه احتمالات است که برای بررسی و تحلیل رویدادهای نادر و احتمالات کوچک استفاده میشود. این مفهوم برای تخمین بزرگترین یا کوچکترین احتمالها در یک توزیع احتمال استفاده میشود. محدودههای دم معمولا به صورت حدود بالا (Upper Bounds) یا حدود پایین (Lower Bounds) بیان میشوند و میزان تضمین را برای احتمالات مورد بررسی فراهم میکنند. این حدود میتوانند به صورت احتمالاتی (با استفاده از نابرابریهای مشهور مانند نابرابری مارکوف و چبیشف) یا به صورت احتمالی دقیق (با استفاده از نابرابریهای مانع و رازبین) بدست آید. محدودههای دم برای ارزیابی ریسکها و تخمین احتمالات کوچک در مسائل مختلف از جمله علوم کامپیوتر، آمار، شبکهها و تئوری اطلاعات استفاده میشوند.
کلام آخر
الگوریتمهای جریان داده در بسیاری از حوزهها مورد استفاده قرار میگیرند، از جمله تحلیل جریانهای حسگری، کاوش دادههای جریانی، تحلیل رویدادها، ترافیک شبکه، پردازش آنلاین تراکنشهای مالی، پیشبینی رفتار کاربران در وب و بسیاری موارد دیگر.
ماهنامه شبکه را از کجا تهیه کنیم؟
ماهنامه شبکه را میتوانید از کتابخانههای عمومی سراسر کشور و نیز از دکههای روزنامهفروشی تهیه نمائید.
ثبت اشتراک نسخه کاغذی ماهنامه شبکه
ثبت اشتراک نسخه آنلاین
کتاب الکترونیک +Network راهنمای شبکهها
- برای دانلود تنها کتاب کامل ترجمه فارسی +Network اینجا کلیک کنید.
کتاب الکترونیک دوره مقدماتی آموزش پایتون
- اگر قصد یادگیری برنامهنویسی را دارید ولی هیچ پیشزمینهای ندارید اینجا کلیک کنید.



















نظر شما چیست؟