




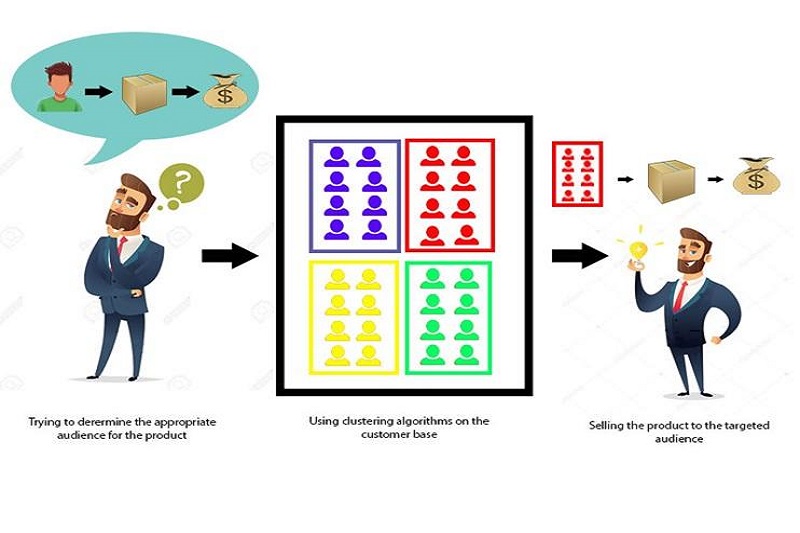
تحلیل خوشهای چیست؟
تحلیل خوشهای یک تکنیک یادگیری ماشین بدون نظارت است که برای شناسایی گروههای مشابه در دادهها استفاده می شود. خوشهها مجموعهای از دادهها هستند که از نظر ویژگیهای مشابه به هم نزدیک هستند. تحلیل خوشهای میتواند برای شناسایی گروههای مشتریان، گروههای کالا و موارد این چنینی استفاده شود.
امروزه، انواع مختلفی از تحلیل خوشهای وجود دارد که هر کدام مزایا و معایب خاص خود را دارند. یکی از رایجترین انواع تحلیل خوشهای، تحلیل خوشهای K-means است. تحلیل خوشهای K-means دادهها را به K خوشه تقسیم میکند، جایی که K تعداد خوشههای مورد نظر است. خوشهها به گونهای انتخاب میشوند که فاصله بین دادهها در هر خوشه کمترین مقدار ممکن باشد.
تحلیل خوشه ای یک ابزار قدرتمند برای شناسایی گروه های مشابه در دادهها است. با این حال، مهم است که توجه داشته باشید که تحلیل خوشهای یک تکنیک یادگیری ماشین بدون نظارت است. به بیان دقیقتر، تحلیل خوشهای نمیتواند به شما بگوید که هر خوشه چیست. شما باید با استفاده از دانش خود در مورد دادهها، معنای خوشهها را تفسیر کنید.
مزایای استفاده از تحلیل خوشهای :
- میتواند برای شناسایی گروههای مشابه در دادهها استفاده شود.
- میتواند برای کاهش پیچیدگی دادهها استفاده شود.
- میتواند برای کشف الگوها در دادهها استفاده شود.
- میتواند برای پیشبینی رفتار دادهها استفاده شود.
معایب تحلیل خوشهای :
- میتواند پیچیده باشد.
- میتواند زمان بر باشد.
- میتواند به دانش زیادی در مورد دادهها نیاز داشته باشد.
- میتواند به دادههای زیادی نیاز داشته باشد.
در تحلیل خوشهای، دادههای ورودی، به صورت بردارهای چند بعدی تعریف میشوند که هر بعد آنها نشاندهنده یک ویژگی است. سپس، با استفاده از الگوریتمهای خوشهبندی، دادههای ورودی به گروههای خوشهای تقسیم میشوند. همانگونه که اشاره کردیم، یکی از مشهورترین الگوریتمهای خوشهبندی، K-Means است که بر اساس مرکزیت خوشهها کار میکند و برای به دست آوردن بهترین تقسیم به تعداد مشخصی از خوشهها، بهینهسازی میکند.
تحلیل خوشهای در بسیاری از حوزهها مثل روانشناسی، علوم اجتماعی، اقتصاد، تجارت الکترونیک و بسیاری زمینههای دیگر، مورد استفاده قرار میگیرد. به عنوان مثال، در علوم اجتماعی میتوان از تحلیل خوشهای برای دستهبندی افراد با ویژگیهای مشابه در یک گروه استفاده کرد. در تجارت الکترونیک، میتوان از تحلیل خوشهای برای دستهبندی مشتریان بر اساس رفتارهای خرید آنها استفاده کرد.
الگوریتم K-Means چیست؟
K-Means یکی از محبوبترین الگوریتمهای خوشهبندی است که برای دستهبندی دادهها به گروههای خوشهای مشابه به کار میرود. در این الگوریتم، ابتدا تعدادی نقطه مرکزی (centroid) به صورت تصادفی ایجاد میشود و سپس دادهها به گروههای خوشهای تقسیم میشوند که نزدیک به مرکز تعیین شده هستند. در ادامه، مراکز جدید محاسبه میشوند و فرایند تقسیم مجدد دادهها بر اساس مراکز جدید انجام میشود. این فرایند به صورت تکراری ادامه مییابد تا مراکز دیگری ساخته نشود و تقسیمبندی نهایی به دست آید.
عملکرد الگوریتم K-Means بر اساس فاصله اقلیدسی (Euclidean Distance) بین نقاط و مراکز محاسبه میشود. فاصله اقلیدسی بین دو نقطه در فضای n بعدی برابر با جذر مربعات فاصله افقی، عمودی و عمقی بین آن دو نقطه است.
مزایای الگوریتم K-Means شامل سادگی و سرعت اجرای آن است. همچنین، به دلیل سادگی محاسبات، این الگوریتم برای دادههای حجیم به خوبی عمل میکند. با این حال، نکتهای که باید در نظر گرفت، این است که K-Means به دلیل اینکه مبتنی بر فاصله اقلیدسی است، برای دادههایی که شکلهای اصلی آنها وارد نیست، عملکرد چندان مطلوبی ندارد. همچنین، اگر تعداد خوشهها درست تنظیم نشود، ممکن است الگوریتم به نتایج نامطلوبی برسد.
آیا K-Means برای دادههایی با شکلهای غیر دوار همیشه نامطلوب است؟
خیر، الگوریتم K-Means برای دادههایی با شکلهای غیر دایرهای همیشه عملکرد ضعیفی ندارد، اما ممکن است در برخی موارد به دلیل نوع دادهها، نتایج نامطلوبی ارائه کند.
در واقع، الگوریتم K-Means برای دادههایی که شکلهای اصلی آنها دوار نیستند، به نحو مناسبی عمل نمیکند، زیرا الگوریتم K-Means بر اساس فاصله اقلیدسی بین نقاط و مراکز محاسبه میشود و به دنبال مراکزی است که نزدیک به مرکز هستند. اما در دادههایی که شکل آنها دوار نیست، فاصله اقلیدسی بین نقاط و مراکز میتواند معنا نداشته باشد و ممکن است به نتایج نامطلوبی منجر شود.
به همین دلیل، برای دادههایی که شکل آنها دوار نیست، روشهای دیگری مانند روش خوشهبندی سلسله مراتبی (Hierarchical Clustering)، روش خوشهبندی مبتنی بر گراف (Graph-based Clustering)، و روش خوشهبندی مبتنی بر شباهت (Similarity-based Clustering) میتوانند بهتر عمل کنند.
چگونه میتوان تعداد خوشهها را به درستی تنظیم کرد؟
تنظیم تعداد خوشهها برای الگوریتم خوشهبندی، یکی از اساسیترین مسائل در این حوزه است. انتخاب تعداد خوشهها باید به گونهای باشد که به دقت و کیفیت خوشهبندی کمک کند. در ادامه چند روش برای تنظیم تعداد خوشهها را بررسی میکنیم:
- روش آرنج (Elbow Method): در این روش، برای تعداد خوشههای مختلف، مقدار SSE سرنام Sum of Squared Errors محاسبه میشود. سپس، نمودار SSE بر حسب تعداد خوشهها رسم میشود و نقطه انتقال شدیدترین کاهش SSE در نمودار به عنوان تعداد بهینه خوشهها در نظر گرفته میشود. نام این روش به دلیل شباهت نمودار SSE با شکل آرنج (Elbow) است.
- روش درختوارهنگار/شاخهبندی (Dendrogram): در این روش که در خوشهبندی سلسله مراتبی (Hierarchical Clustering) استفاده میشود، نمودار سلسله مراتبی خوشهها درختواره رسم میشود. سپس با مشاهده نمودار، تعداد خوشههایی که با توجه به مسئله مورد بررسی، بهینه به نظر میرسد، انتخاب میشود.
- روش شبکههای عصبی (Neural Networks): در این روش، با استفاده از شبکههای عصبی، تعداد خوشههای بهینه برای دادهها تعیین میشود. در این روش، شبکههای عصبی با تعداد خوشههای مختلف آموزش داده میشوند و تعداد خوشههایی که عملکرد بهتری از خود نشان میدهد، به عنوان تعداد بهینه خوشهها در نظر گرفته میشود.
- روش اندازهگیری خودکار (Automatic Measurement): در این روش، تعداد خوشهها به صورت خودکار توسط الگوریتمهای خوشهبندی مشخص میشود. به عنوان مثال، در روش DBSCAN، تعداد خوشهها به صورت خودکار تعیین میشود.
در هر صورت، تنظیم تعداد خوشهها یک مسئله پیچیده است و باید با توجه به خصوصیات دادهها و مسئله مورد بررسی، با دقت و دانش تخصصی انجام شود.
آیا تنظیم تعداد خوشهها برای دادههای با ابعاد زیاد مشکلاتی دارد؟
بله، تنظیم تعداد خوشهها برای دادههای با ابعاد زیاد ممکن است به دلیل وجود ابعاد بیش از حد، به یک مسئله پیچیده تبدیل شود. در واقع، با افزایش تعداد ابعاد، حجم دادهها بسیار بزرگ میشود و این میتواند باعث ایجاد مشکلاتی در تحلیل دادهها شود. به عنوان مثال، در دادههای با ابعاد بالا، مفهوم فاصله و شباهت بین دادهها بسیار پیچیدهتر میشود و الگوریتمهای خوشهبندی که بر اساس فاصله و شباهت عمل میکنند، ممکن است به نتایج نامطلوبی منجر شوند.
برای مقابله با این مشکل در دادههای با ابعاد بالا، میتوان از روشهایی مانند کاهش بعد (Dimensionality Reduction) استفاده کرد. این روشها با کاهش تعداد ابعاد دادهها، میتوانند به دقت و کیفیت خوشهبندی کمک کنند. به عنوان مثال، میتوان از روشهای PCA سرنام (Principal Component Analysis) و t-SNE سرنام (t-Distributed Stochastic Neighbor Embedding) برای کاهش بعد دادهها استفاده کرد.
اکنون، به این پرسش مهم میرسیم که آیا روشهای کاهش بعد همیشه بهترین راهحل برای خوشهبندی دادههای با ابعاد زیاد هستند؟ پاسخ منفی است، روشهای کاهش بعد همیشه بهترین اه حل برای خوشهبندی دادههای با ابعاد زیاد نیستند. در حقیقت، استفاده از روشهای کاهش بعد برای خوشهبندی دادههای با ابعاد زیاد ممکن است به نتایج نامطلوبی منجر شود. به عنوان مثال، در برخی موارد، استفاده از روشهای کاهش بعد ممکن است باعث از دست رفتن برخی اطلاعات مهم در دادهها شود که میتواند باعث نامطلوب شدن نتایج خوشهبندی شود.
به علاوه، استفاده از روشهای کاهش بعد برای دادههای با ابعاد زیاد، ممکن است با مشکلاتی مانند افزایش زمان محاسبات و افزایش پیچیدگی مدل همراه باشد. در برخی موارد، استفاده از روشهای کاهش بعد ممکن است باعث به وجود آمدن خطاهایی در نتایج خوشهبندی شود.
به همین دلیل، استفاده از روشهای کاهش بعد باید با دقت و با توجه به خصوصیات دادهها و مسئله مورد بررسی، انجام شود. در برخی موارد، روشهای دیگری مانند خوشهبندی سلسله مراتبی (Hierarchical Clustering)، خوشهبندی مبتنی بر گراف (Graph-based Clustering)، و روشهای خوشهبندی مبتنی بر شباهت (Similarity-based Clustering) که در ادامه به آنها اشاره خواهیم کرد، میتوانند بهترین راهحل برای خوشهبندی دادههای با ابعاد زیاد باشند.
در کل، تنظیم تعداد خوشهها برای دادههای با ابعاد بالا یک چالش است و به دقت و تخصص تحلیل دادهها و انتخاب روش مناسب برای خوشهبندی نیاز دارد.
چه روشهای دیگری برای خوشهبندی وجود دارد؟
علاوه بر الگوریتم K-Means، روشهای دیگری برای خوشهبندی وجود دارند. در زیر به برخی از این روشها اشاره میکنم:
- روش خوشهبندی سلسله مراتبی (Hierarchical Clustering): در این روش، خوشهها به شکل سلسله مراتبی تشکیل میشوند. در ابتدا، هر داده به عنوان یک خوشه در نظر گرفته میشود و سپس خوشهها به صورت بازگشتی به گروههای کوچکتر تقسیم میشوند تا به گروههای نهایی برسیم. این روش به دلیل قابلیت تفسیری بالا و عدم نیاز به تعیین تعداد خوشهها، برای بررسی دادههای کم حجمی مناسب است.
- روش خوشهبندی مبتنی بر گراف (Graph-based Clustering): در این روش، دادهها به عنوان گرههای یک گراف در نظر گرفته میشوند و خوشهها به عنوان زیرگرافهایی که بیشترین تعداد یال را دارند، تشکیل میشوند. این روش برای دادههایی که دارای ساختار گرافی هستند، مناسب است.
- روش خوشهبندی مبتنی بر توزیعهای احتمالاتی (Probabilistic Clustering): در این روش، فرض بر این است که دادهها از توزیعهای احتمالی خاصی پیروی میکنند. سپس با استفاده از مدلهای احتمالی، خوشهها تشکیل میشوند. این روش برای دادههایی که قابلیت تخمین توزیع احتمالی آنها وجود دارد، مناسب است.
- روش خوشهبندی مبتنی بر شباهت (Similarity-based Clustering): در این روش، دادهها بر اساس ویژگیهایشان به یکدیگر دستهبندی میشوند. این روش برای دادههایی که نمیتوانند به صورت خطی دستهبندی شوند، مناسب است.
- روش خوشهبندی مبتنی بر شبکههای عصبی (Neural Network-based Clustering): در این روش، شبکههای عصبی به عنوان یک روش برای خوشهبندی دادهها به کار میروند. با آموزش شبکههای عصبی، خوشههای بهتری ایجاد میشوند.
ماهنامه شبکه را از کجا تهیه کنیم؟
ماهنامه شبکه را میتوانید از کتابخانههای عمومی سراسر کشور و نیز از دکههای روزنامهفروشی تهیه نمائید.
ثبت اشتراک نسخه کاغذی ماهنامه شبکه
ثبت اشتراک نسخه آنلاین
کتاب الکترونیک +Network راهنمای شبکهها
- برای دانلود تنها کتاب کامل ترجمه فارسی +Network اینجا کلیک کنید.
کتاب الکترونیک دوره مقدماتی آموزش پایتون
- اگر قصد یادگیری برنامهنویسی را دارید ولی هیچ پیشزمینهای ندارید اینجا کلیک کنید.



















نظر شما چیست؟