




11 مهارت ضروری یک مهندس داده در سال 2023 چیست؟
در بحبوحه همهگیری کرونا، شاهد رشد عظیم اطلاعاتی بودیم که روی زیرساختهای ابری ذخیرهسازی شدند. بهطوریکه ارائهدهندگان خدمات ابری مجبور به بازبینی استراتژیها و سرویسهای ذخیرهساز اطلاعات، پروتکلهای امنیتی و کانالهای ارتباطی شدند. یکی از دلایل این موضوع، علاقهمندی سازمانها به محیطهای چند ابری است؛ بهطوریکه گارتنر پیشبینی میکند بیش از 85 درصد سازمانها تا سال 2025 بهشکل گسترده از زیرساختهای ابری استفاده خواهند کرد. در سال 2023، تعداد مشاغل مرتبط با علم داده رشد چشمگیری خواهند داشت، اما دو عنوان شغلی مهندسی داده و MLOp بیش از مشاغل دیگر مورد توجه قرار خواهند گرفت. پژوهشهای انجامشده توسط موسسات مختلف نشان میدهند یک مهندس داده، علاوه بر مهارتهای استانداردی که به آنها نیاز دارد باید بهفکر یادگیری کار با فناوریهای جدید، نحوه تعامل با منابع مختلف ذخیرهسازی اطلاعات و زیرساختهای ابری باشد. با این مقدمه، به سراغ مهارتها و الزاماتی میرویم که یک مهندس داده در سال 2023 به آنها نیاز دارد.
11. اسکریپتنویسی
بله، یک مهندس داده باید در زمینه اسکریپتنویسی مهارت داشته باشد. لینوکس، بش (Bash)، پاورشل، تایپاسکریپت، جاوااسکریپت و پایتون از مهارتهای ضروری هستند که یک مهندس داده در سال 2023 باید داشته باشد. علاوه بر این، باید توانایی کار با فناوریهای دادهمحور و متنمحور مثل CSV، TSV، JSON، Avro، Parket، XML، ORC و غیره داشته باشد. مهندسان داده برای طراحی و ساخت خط انتقال دادهها باید در زمینه ابزارهای ETL / ELT و تکنیکهای مرتبط با آنها مهارت سطح بالایی داشته باشند.
10. برنامهنویسی
در سال گذشته، پایتون، جاوا، سیشارپ و سیپلاسپلاس، زبانهای برنامهنویسی اصلی دنیای مهندسی ماشین بهشمار میرفتند، اما انتظار میرود این روند در سال 2023 میلادی تغییر پیدا کند. بهطوریکه زبانهای برنامهنویسی Go، Ruby، Rust و Scala به جمع زبانهای برنامهنویسی محبوب در این زمینه وارد شوند. زبانهای قدرتمندی که قابلیت کار با فناوریهایی مثل آپاچی اسپارک (Apache Spark) را دارند و قادر هستند با زیرساختهای ابری مثل Amazon Glue و DataBricks کار کنند. کار با جریان دادههای بلادرنگ تولیدشده در شبکههای اجتماعی، پردازش زبان طبیعی، ایمیل، سرویسها و سیستمهای ابرمحور نیز در سالهای آتی مورد توجه قرار خواهند گرفت.

9. DevOps
یکی از مهارتهای مهمی که باید بهعنوان یک مهندس داده بهفکر یادگیری آن باشید، دوآپس است. این حوزه شامل چرخه عمر توسعه نرمافزار (SDLC)، توسعه مستمر (CD) و یکپارچهسازی مداوم (CI) بههمراه تکنیکها و ابزارهایی مثل جنکینز، گیت و گیتلب است. این مهارتهای کاربردی بههمراه DataOps و Data Governance باعث میشوند تا دادههای باکیفیتی تولید شوند که نتایج دقیقتری را بههمراه دارند.
8. SQL
یک مهندس داده برای انجام درست وظایف خود نیازمند آمادهسازی طرحواره و کار بر مبنای آن است. بد نیست بدانید که سیستمهای ابرمحور، پشتیبانی بهتری از SQL از طریق واسطهای برنامهنویسی کاربردی بهعمل آوردهاند تا مهندسان بتوانند بهشکل دقیقتری کوئریهای خود را بنویسند. سیستمهای مدیریت پایگاه داده رابطهای (RDBMS) همچنان نقش مهمی در ذخیرهسازی دادهها دارند، از اینرو نباید از فکر یادگیری کار با این سیستمها غافل شوید.
7. NoSQL
متاسفانه، برخی از متخصصان و حتا سازمانها به این نکته اشاره دارند که هدوپ دیگر فناوری مهمی نیست، زیرا ما بهسمت ابر حرکت میکنیم. فضای ابری مملو از دادههای بدون ساختار یا نیمهساختاریافته (بدون طرحواره SQL) است. در واقع، NoSQL، چه مبتنی بر منبعباز آپاچی یا MongoDB و Cassandra باشد، و چه در سایر موارد، به پلتفرمی نیاز است که توانایی کار با حجم عظیمی از دادههای بدون ساختار را داشته باشد.
بهعنوان یک مهندس داده، باید در مورد نحوه دستکاری جفتهای کلید-مقدار و اشیایی مثل JSON ،Avro یا Parquet اطلاعات کافی داشته باشید. از اینرو، باید درباره فناوریهایی که مبتنی بر NoSQL هستند، دانش کافی داشته باشید.
6. توانایی ساخت دقیق خطوط انتقال داده
دریاچه داده (Data Lakes) از اصطلاحات مهم دنیای دادهمحور است که همراه با فناوریهای مختلف و گاهیاوقات جدیدی مثل DataBricks Lakehouse و Snowflakes Data Cloud است. کار با جریانهای دادهای بلادرنگ، محاورههای قابل اجرا روی انبارهای داده، JSON ،CSV و دادههای خام از وظایف روزمره یک مهندس داده است. روش و مکانی که مهندسان دادهها را ذخیرهسازی میکنند، اهمیت زیادی دارد. از اینرو، باید با مجموعه مهارتها و ابزارهای مهندسی داده (ETL/ELT) که برای این منظور در دسترس هستند، آشنا باشید.

5. فراخودکارسازی (Hyper Automation)
مهندسان داده، وظایف مشخصی دارند، اما وظایف دیگری مثل زمانبندی و اجرای وظایف و پیگیری رویدادها نیز به آنها محول میشود. بهطور معمول، یک مهندس داده زمان کافی برای انجام برخی کارها را ندارد و باید به سراغ ابزارهای خودکارسازی کارها برود. این متخصصان برای انجام این وظایف باید توانایی کار با ابزارهایی مثل Scripting و Data Pipelines را داشته باشند. گارتنر در این باره میگوید: «تیمهای موفق علم دادهها از ابر و خودکارسازی غافل نمیشوند. این دو راهکار قدرتمند به آنها کمک میکند تا کیفیت انجام کارها را بهبود بخشند، روند انجام فرآیندهای تجاری را تسریع کنند و با سرعت بیشتری تصمیمات کلیدی را اتخاذ کنند».
4. مصورسازی
تجزیهوتحلیل دادههای اکتشافی (EDA) سرنام Exploratory Data Analysis، اکنون به یکی از وظایف مهم مهندسان داده تبدیل شده است. راهکار فوق به مهندسان داده کمک میکند تا اطلاعات پیچیده و فنی را به زبان سادهای شرح دهند. به همین دلیل، یک مهندس داده باید توانایی کار با ابزارهایی مثل SSRS، Excel، PowerBI، Tableau، Google Looker، Azure Synapse را داشته باشد.
3. یادگیری ماشین و هوش مصنوعی
یک مهندس داده باید درباره اصطلاحات و الگوریتمهای دنیای هوش مصنوعی و یادگیری ماشین دانش اولیه داشته باشد. به بیان دقیقتر، حداقل با کتابخانههای پایتون مثل پانداس، نامپای و SciPy، آشنا باشد. ابزارهایی که از طریق محیط توسعه یکپارچه ژوپیتر نوتبوک در دسترس قرار دارند. با این توصیف، نهتنها باید نحوه کار با این ابزارها را بدانید، بلکه باید دانش کافی درباره ژوپیتر نوتبوک را داشته باشید. علاوه بر این، بهتر است نحوه کار با ابزارهای ابرمحوری مثل AWS Sagemaker ،HDInsight مایکروسافت یا مجموعه ابزارهای DataLab گوگل را داشته باشید تا بتوانید با مجموعه دادههای پیچیده بهتر کار کنید.
2. محاسبات چند ابری
محیطهای چند ابری، بهشکل گستردهای رواج پیدا کردهاند و تقریبا همه شرکتها و سازمانهای بزرگ از ترکیب چند ابر برای انجام کارهای روزانه استفاده میکنند. به بیان دقیقتر، شرکتهایی که تمایل ندارند تمام اطلاعات خود را در اختیار ارائهدهندگان خدمات ابری قرار دهند، ترجیح میدهند به سراغ چند ابری بروند. آمارها نشان میدهند تقریبا 76 درصد شرکتها از ابر عمومی و خصوصی استفاده میکنند تا بتوانند از مزایای هر دو محیط به بهترین شکل استفاده کنند. بر مبنای این تعریف، باید بگوییم بهعنوان یک مهندس داده باید درک خوبی از فناوریهای اساسی داشته باشید که محاسبات ابری را شکل میدهند. از اینرو، دانش خود درباره نحوه پیادهسازی IaaS ،PaaS و SaaS را افزایش دهید.
1. آشنایی با مباحث مرتبط با تجزیهوتحلیل گرافها
بهطور کلی تجزیهوتحلیل دادههای عددی، با هدف دستیابی به بینشهای دقیق و حل مسائل انجام میشوند. در فرآیند تجزیهوتحلیل گراف، روابط بین موجودیتها، بهجای دادههای عددی تحلیل میشود. الگوریتمهای گراف و پایگاه دادههای گرافی و تحلیل آنها در زمینههایی مثل تجزیهوتحلیل شبکههای اجتماعی، تشخیص تقلب، شناسایی عملکرد زنجیره تامین و بهینهسازی موتورهای جستوجو استفاده میشود.
برای درک موضوع تجزیهوتحلیل گراف، ابتدا باید بدانیم که گراف چیست؟ گراف یک اصطلاح ریاضی است که روابط بین نهادها را نشان میدهد. گرافها انواع مختلفی بهشرح زیر دارند:
- گرافهای جهتدار (Directed graphs): همه یالها از یک گره بهسمت گره دیگر هدایت میشوند. به این نوع گرافها directed network گفته میشود. این نوع گرافها روابط نامتقارن بین گرهها را نشان میدهند.
- گرافهای بدون جهت (Undirected graphs): تمام یالها یک گره را به گره دیگر متصل میکنند، اما جهت رابطه مشخص نیست. این گراف، شبکه بدون جهت نامیده میشود. گرافهای بدون جهت، روابط متقارن را نشان میدهند. شکل ۱، تفاوت این دو گره را نشان میدهد.
- گرافهای وزندار (Weigh graphs): یک گراف وزندار، یالهایی دارد که وزن آنها را تعریف میکند. این وزنها کوتاهترین مسیر را نشان میدهند.
- گرافهای چرخشی (Cyclic graphs): مسیری از حداقل یک گره بهسمت همان گره را نشان میدهد.
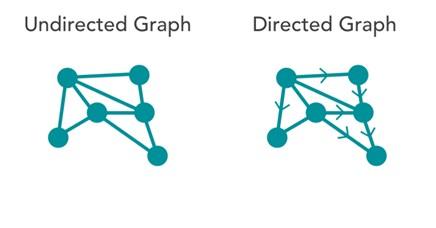
شکل 1
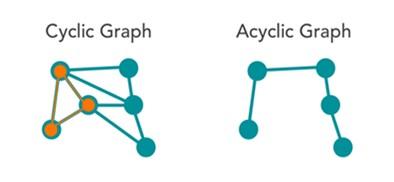
شکل 2
شکل ۲، گرافهای فوق را نشان میدهد. یکی از مهارتهای مهمی که یک مهندس داده باید داشته باشد، توانایی تحلیل گراف است که تحلیل شبکه نیز نامیده میشود؛ این تحلیلها با هدف نشان دادن روابط بین موجودیتهایی مثل مشتریان، محصولات، اطلاعات و غیره استفاده میشوند. لازم به توضیح است، سازمانها برای بهدست آوردن بینشهایی که میتوانند در بازاریابی یا شبکههای اجتماعی استفاده شوند از مدلهای گرافی استفاده میکنند. بد نیست بدانید که آمادهسازی و تحلیل گرافها یکی از سودآورترین کارهایی است که یک مهندس یا تحلیلگر داده انجام میدهد.
انواع مختلف تحلیل گراف
روشهای مختلفی برای تحلیل گرافها و الگوریتمهای گراف وجود دارد. مهندسان داده برای تحلیل گرافها از روشهای زیر استفاده میکنند:
- تجزیهوتحلیل مرکزیت (Centrality): این تحلیل میزان مهم بودن یک گره را در اتصالات یک شبکه گرافی مشخص میکند و کمک میکند با استفاده از الگوریتم PageRank تاثیرگذارترین افراد در یک شبکه اجتماعی یا صفحات وب را تخمین زد. شکل ۳، شمای کلی تحلیل مرکزیت را نشان میدهد.

شکل 3
- تشخیص انجمنی (Community): از فاصله و تراکم روابط بین گرهها میتوان گروههایی از گرهها را پیدا کرد که بهشکل مرتب در یک شبکه با یکدیگر تعامل دارند. تجزیهوتحلیل انجمنی با الگوهای تشخیص رفتار جوامع مرتبط است. شکل ۴، نمای کلی تحلیل فوق را نشان میدهد.

شکل 4
- تحلیل اتصال (Connectivity): مشخص میکند دو گره با چه شدت یا ضعفی به یکدیگر متصل هستند. بهشکل خلاصه، هرچه تعداد یالهای مستقیم و غیرمستقیم دو گره بیشتر باشد، اتصال دو گره بیشتر است.
- تحلیل مسیر (Path): روابط بین گرهها را بررسی میکند. این تحلیل بیشتر در زمینه شناسایی کمترین مسافت استفاده میشود.
- پیشبینی پیوند (Link Prediction): با محاسبه همسایگی و فرم ساختاری گرهها، روابط جدید یا اتصالات موجود را که روی گراف مشخص نشدهاند تخمین میزند. شکل ۵، نمای کلی تحلیل پیشبینی پیوند را نشان میدهد.

شکل 5
یکی از کاربردهای اصلی تحلیل گراف، مربوط به سیستمهای توصیهگر است. به احتمال زیاد در شبکههای اجتماعی به مواردی مثل «افرادی که ممکن است بشناسید» یا «آهنگهایی که ممکن است دوست داشته باشید» برخورد کردهاید. این توصیهها بر مبنای «فیلتر کردن مشارکتی» (Collaborative Filtering) انجام میشود که روشی معمول است که موتورهای توصیهگر از آن استفاده میکنند. تحلیلهای گراف نقش مهمی در زمینه شناسایی الگوها دارند.
معروفترین پایگاه دادههای گراف
مهندسان داده به ابزارهای پایگاه داده گرافی برای تجزیهوتحلیل پیشرفته گرافها نیاز دارند. پایگاه دادههای گرافی، گرهها را به یکدیگر متصل میکنند و روابط بین یالها را بهصورت گرافهایی ایجاد میکنند که میتوانند در کوئریها مورد استفاده قرار گیرند. از پایگاه دادههای برجسته گراف باید به Amazon Neptune، ArangoDB، Cayley، DataStax، FlockDB، Neo4j، OrientDB و Titan اشاره کرد.
الگوی معماری داده گرافی (Graph) یکی از انواع پایگاههای داده NoSQL است که هنگام ساخت برنامههای هوشمندی که نیازمند تحلیل روابط بین اشیاء یا مشاهده تمامی گرهها در یک گراف هستند، مورد استفاده قرار میگیرد. معماری فوق برای ذخیره موثر گرههای گراف و ارتباطات بهینه بین آنها کارآمد است. در این حالت، دانشمندان داده میتوانند روی دادههایی که بهشکل یک گراف ذخیره شدهاند، کوئریهای موردنظر را اجرا کنند.
این نوع پایگاههای داده برای هر کسبوکاری که دادههایی دارد که ارتباطات پیچیدهای میان آنها وجود دارد، مفید است.
پایگاههای داده گرافی شامل دنبالهای از گرهها و ارتباطات هستند که ترکیب آنها با یکدیگر یک گراف را ایجاد میکند. معماری داده key-value store شامل دو فیلد key و value است. در مقابل، در یک پایگاه داده گرافی از سه فیلد اساسی داده به نامهای گره، روابط و خصلت روابط استفاده میشود.
زمانی که عناصر زیادی داریم که روابط پیچیدهای دارند و هر یک خصلتهای مختصبهخود هستند، استفاده از پایگاه داده گراف، مناسب است. بهطوریکه امکان اجرای محاورههای ساده وجود دارد و میتوان نزدیکترین همسایه یا الگوی خاصتر و پیچیدهتری را شناسایی کرد. بهطور معمول، گرههای گراف بیانگر اشیاء دنیای واقعی مثل اسامی هستند. گرهها میتوانند افراد، سازمانها، شماره تلفن، صفحات وب، کامپیوترهای موجود روی یک شبکه و موارد اینچنینی باشند. اکنون اجازه دهید برخی از پراستفادهترین پایگاههای داده گرافی و ویژگی آنها را بررسی کنیم.
Neo4j
شناختهشدهترین سیستم مدیریت پایگاه داده متنباز گرافی است که عملکرد و مستندات خوبی در مورد آن وجود دارد. برای استفاده از این پایگاه داده باید به زبان Cypher مسلط باشید. Neo4j مبتنی بر مقیاسپذیری افقی است که فرآیند خواندن را بر مبنای الگوی Master-Slave انجام میدهد تا سرعت خواندن اطلاعات بیشتر شود، اما سرعت نسبتا کندی در زمینه پاسخگویی به درخواستها دارد. از اینرو، باید بگوییم Neo4j در مورد کاربردهایی که عملیات نوشتن کم و خواندن زیاد دارند، مناسب است. در این پایگاه داده از تکنیک بخشبندی داده (Sharding) استفاده نمیشود، زیرا تقسیم بهینه یک گراف بزرگ بین چند ماشین هزینهبر است. سهولت در استفاده، کاهش میزان استفاده از حافظه اصلی، مناسب برای رایانش ابری، پشتیبانگیری حرفهای، طرحواره انعطافپذیر، قابلیت استفاده از آن با زبانهای مختلفی که یک مهندس داده باید با آنها آشنا باشد و پشتیبانی از چارچوبهای لاراول، اسپرینگ و کانگو از مزایای آن است.
OrientDB
یکی دیگر از پایگاه دادههای معروف در این زمینه است که از هر دو معماری سندگرا و گراف پشتیبانی میکند. OrientDB یکی از پایگاه دادههای قدرتمد در اکوسیستم NoSQL است. از مزایای شاخص OrientDB باید به پشتیبانی کامل از ACID، پشتیبانی کامل از زبان SQL، امکان استفاده از RESTful بدون واسطه، سرعت بالا، چندسکویی بودن، متنباز بودن، قابلیت مدیریت ساختار گراف و نمودارها بهشکل بومی، توزیعپذیری، قابلیت درج در برنامههای کاربردی جاوا و غیره اشاره کرد.
TITAN
TITAN یک پایگاه داده توزیعشده و مقیاسپذیر گرافی است. تیتان برای مرتبسازی دادههای گراف و کوئری روی گراف بهینه مورد استفاده قرار میگیرد. این پایگاه داده توانایی پردازش میلیاردها گره و یال بهشکل توزیعشده میان چند ماشین را دارد. از مزایای این پایگاه داده باید به مقیاسپذیری ارتجاعی و خطی برای مدیریت حجم زیادی از دادهها، توزیع و تکثیر دادهها با هدف دستیابی به عملکرد بهتر و تحمل خطا، پشتیبانی از ACID، پشتیبانی از ذخیرهسازی بکاند مثل HBase، BerkeleyDB، Cassandra، پشتیبانی از تجزیهوتحلیل دادههای حجیم گرافی، گزارشدهی و فرآیند ETL، پشتیبانی از اسپارک، هدوپ و Apache Giraph اشاره کرد.
ArangoDB
این پایگاه داده میتواند یک شیء JSON را بهعنوان ورودی درون یک مجموعه ذخیره کند. از اینرو، نیازی به تفکیک بخشهای مختلف JSON نیست. به همین دلیل، دادههای ذخیرهشده، میتوانند ساختار درخت دادههای XML را ارثبری کنند. از ویژگیهای شاخص پایگاه داده فوق باید به نصب آسان، انعطافپذیری مدلسازی دادهها، زبان کوئری قوی برای بازیابی و ویرایش دادهها، قابلیت استفاده از آن بهعنوان یک سرویسدهنده سرور، قابلیت تکثیر و توزیع دادهها و غیره اشاره کرد.
ماهنامه شبکه را از کجا تهیه کنیم؟
ماهنامه شبکه را میتوانید از کتابخانههای عمومی سراسر کشور و نیز از دکههای روزنامهفروشی تهیه نمائید.
ثبت اشتراک نسخه کاغذی ماهنامه شبکه
ثبت اشتراک نسخه آنلاین
کتاب الکترونیک +Network راهنمای شبکهها
- برای دانلود تنها کتاب کامل ترجمه فارسی +Network اینجا کلیک کنید.
کتاب الکترونیک دوره مقدماتی آموزش پایتون
- اگر قصد یادگیری برنامهنویسی را دارید ولی هیچ پیشزمینهای ندارید اینجا کلیک کنید.























نظر شما چیست؟